Mobilen som distribusjonskanal for hyperlokal jounalistikk
Samandrag: Med Veven har avisa fått nettsida som den viktigaste vegen ut til brukarane, og den mobile versjonen vert gjerne lest like ofte som den som ein finn på standard nettlesarar. I denne konteksten er det eit behov for avisene å utvikle nye produkt, der brukarane får tilgang til eller vert lokka til innhaldet på nye måtar og gjerne óg frå ein rikare innhaldsbase. I fleire år har det vore interesse for lokasjonsbasert innhaldspresentasjon som ein måte å vende seg til brukaren. Fleire har óg investert i søkefunksjonar som gjev brukarar tilgang til gamle nyheiter frå arkivet. I eit designvitskapleg prosjekt for ein avisorganisasjon har vi utvikla ein mobil applikasjon som finn hyperlokale nyheiter for ein brukar henta frå avisas arkiv. Avisartiklane som brukaren får presentert omhandlar ein lokasjon som ligg maksimalt 150 meter vekke frå brukaren. Tilgangen til interessante artiklar vert gjeve til brukaren gjennom ei ordsky der ord er vekta etter frekvens i dei utvalde artiklane balansert mot kor nær artiklane med det aktuelle ordet er brukarens plassering. Brukaren klikkar på eit ord i ordskya, får ei liste over artiklar og vel ein interessant artikkel. Vi ser her på avisa som ein organisasjon med eit sterkt innovasjonsbehov, der informasjonssystemet hovudsakleg gjev kundane tilgang til nyheiter i digital form laga i journalistisk arbeid, moderert av redaktørar, presentert i samspel med marknadsføring og til slutt gjort tilgjengeleg gjennom ein nettlesar på mobilen eller pcen. For å vurdere potensialet til ordskyteknologien i ei aviskontekst intervjua vi 5 tilsette i BT i rollene journalist, redaktør og marknadsføringsansvarleg. Dette har gjeve oss innsikter i korleis bransjen vil sjå på denne spesifikke appen, men óg generelt potensialet til lokasjonsbaserte teknologiar i samspel med bruk av eit rikt arkiv for presentasjon av journalistikk.
Innleiing
Dagens avisorganisasjonar strevar hardt med å endre seg frå å vere ein bransje der produktet hovudsakleg var trykte nyheiter og anna informasjon på papir til journalistikk presentert i digitale kanalar. Kundane deira abonnerte gjerne på avisa og fikk den levert heime på døra eller kjøpte papiravisa i ein kiosk eller butikk. Med Veven har avisa fått nettsida som den viktigaste vegen ut til brukarane, og den mobile versjonen vert gjerne lest like ofte som den som ein finn på standard nettlesarar. Den økonomiske modellen er ei utfordring for avisene som legg stoffet sitt ut på nett. Avisene har i stor grad utvikla betalingsveggar og digitale abonnement (Høst, 2016), men det er uklart om dette er nok, sidan lesarane no i veldig stor grad kjem til nyheitene via sosiale medium (Newman et al, 2016). Det å vere til stade i desse kanalane er derfor viktig for avisene. Men andre vegar til nyheitene må óg utforskast, så det er i interessa til avisene å utvikle nye tenesteprodukt, der brukarane blir styrt til innhaldet på nye måtar.
I fleire år har det vore interesse for lokasjonsbasert innhaldspresentasjon generelt, og lokale nyheiter spesielt. Dette er inspirert av trua på at lokalavisene har ein type nyheiter som er viktig for lesarane fordi dei grip direkte inn i dagleglivet deira (Nyre, 2014; Hess & Waller, 2016). Aviser prøver óg ulike tiltak for å gjere arkivet tilgjengeleg for lesarane. Fleire har investert i søkefunksjonar som gjev brukarar tilgang digitale kopiar av gamle papiraviser (for eksempel den norske avisa VG (1)). Dette kan for nokre aviser dreie seg om fulle årgangar langt over 100 år tilbake (for eksempel Trønderavisa (2)).
I lys av dette har vi utvikla ein mobil applikasjon som finn hyperlokale nyheiter (dvs. som er knytt til ei bestemt gate eller kvartal eller liknande) for ein brukar henta frå avisas arkiv. Avisartiklane som brukaren får presentert omhandlar ein lokasjon som ligg maksimalt 150 meter vekke frå brukaren. Tilgangen til interessante artiklar vert gjeve til brukaren indirekte gjennom ei ordsky der ord er vekta etter frekvens i dei utvalde artiklane og etter kor nær artiklane med det aktuelle ordet er brukarens plassering. Brukaren klikkar på eit ord i ordskya, får ei liste over artiklar og vel ein interessant artikkel.
Ordskykonseptet har vi tidlegare prøvd ut gjennom ein app (PediaCloud) som gjer det same med lokaliserte Wikipedia-artiklar. I ei brukarevaluering av denne versjonen gjennomført i London 2014 vart det avdekt at brukarane opplevde denne ordskytilnærminga som annleis enn kartbaserte tenester, og at dei ofte ved lukketreff fann uventa innhald som var spennande og interessant (Tessem, Bjørnestad, Chen & Nyre, 2015).
Ordskytilnærminga kunne óg vere interessant for avismedia, så vi ønskte å evaluere potensialet for ei teneste basert på lokasjonsordsky i denne bransjen. Vi implementerte derfor denne funksjonaliteten for eit utval av Bergens Tidendes (BT) artiklar frå 2012-2015, avgrensa til dei artiklane som BT har kategorisert som lokalnytt. Vi gav artiklane ein presis lokasjon ved å bruke data frå Statens Kartverk og google.com og brukte i tillegg teknikkar frå informasjonsgjenfinningsfeltet til å vekte og sortere artiklar som appen fann ved brukarens lokasjon.
I dette arbeidet har vi sett på avisa som ein organisasjon som sel eit digitalt produkt, der informasjonssystemet gjev kundane tilgang til dette produktet laga i journalistisk arbeid, moderert av redaktørar, presentert i samspel med marknadsføring og til slutt gjort tilgjengeleg gjennom ein nettlesar på mobilen eller pcen. Denne appen blir dermed ein del av eit designvitskapleg prosjekt der vi først og fremst utforskar korleis ein kan utvikle ordskyteknologien som ein del av avisas informasjonssystem. Ein sekundær motivasjon har vore å forstå korleis bransjen kan tenkje seg å utnytte lokasjonsbaserte teknologiar kopla med det rike arkivet dei har av nyheiter. For å evaluere teknologien intervjua vi 5 tilsette i BT i rollene journalist, redaktør og marknadsføringsansvarleg.
Vidare i denne artikkelen skildrar korleis vi implementerte systemet, kalla Skynytt, basert på ei vidareutvikling av Wikipedia-versjonen (PediaCloud), og presenterer analysar av BTrepresentantanes responsar på ei slik teneste. Vi startar med ein presentasjon av bakgrunnen for prosjektet i seksjon 2 og held fram med ei teknisk skildring i seksjon 3. Datainnsamling og analyser vert presentert i seksjon 3, før vi avsluttar med ein diskusjon i seksjon 4 og konklusjon i seksjon 5.
Bakgrunn
Lokasjonsorienterte medium
I Noreg finst det eit stort akademisk fagmiljø som driv med systemdesign eller mediedesign (Nyre., 2014) knytt til lokasjon, kopla til visuelt og lydleg innhald og journalistikk. Fagerjord (2015) presenterer ein mobilapp for lytting til kyrkjemusikk i dei kyrkjene den vart komponert. Liestøl (2009) utforskar 3D-grafikkdisplay for visning av arkeologiske utgravingar; Hoem (2009) utforskar korleis kommunikasjonsmønster knytt til blant anna lokasjon kan gje bidrag til utforming av kommunikasjonssystema; Løvlie (2011) skapte Textopia, ei teneste med skriftlege og oppleste utdrag frå norsk skjønnlitteratur som skildrar stader i Oslo. LocaNews utforska lokasjonssensitiv lokal journalistikk, og prototypen vart testa i bygda Voss på Vestlandet. Nyheitene vart skrivne for smarttelefonar, med tre ulike versjonar av den same saka, der lesaren får presentert ein versjon som passar til kor nær saka er (Nyre et.al., 2012). Amplifon var ein proof-of-concept prototype som utforska lokasjonssensitive radionyheiter til bruk på offentleg transport. Det vart gjort testar i Bergen langs Bybanen (Nyre, 2015). Tilhører utforskar brukarens fordjuping i mikroposisjonerte lydforteljingar. Ein utvikla i dette prosjektet ei fleirlags fiktiv lydforteljing der historia brukaren høyrer endrast i høve til tilhøyrarens rørsler. Tilhøyrarane brukte støydempande høyretelefonar. Det vart samla kvantitative og kvalitative data frå 42 brukarar (Hoem et al., 2016).
Pediacloud
Appen PediaCloud er utgangspunktet for den vidareutviklinga til Skynytt vi drøftar her. Den vart i si tid utvikla for å studere korleis ein kunne bruke informasjon frå den semantiske veven til å skape ein ny form for inngang til innhald frå Wikipedia (Tessem, Johansen & Veres, 2013; Tessem, Bjørnestad, Chen & Nyre, 2015). Når ein brukar er på ein lokasjon finn appen artiklar i Wikipedia som er geotagga nær lokasjonen til brukaren. Dette skjer ved at ein finn lokasjonsinformasjon som er lagra på DBpediatenesta, ei teneste som lagrar metainformasjon om Wikipedia i form av såkalla RDF-trippel (RDF = Resource Description Framework) (Hitzler et al., 2010). Eit RDF-trippel består av maskinleseleg informasjon representert som (subjekt,relasjon,objekt). Eit eksempel på geotagginginformasjon i eit slikt RDF-trippel er (http://dbpedia/resource/Bryggen,http://www.w3.org/2003/01/geo/wgs84_pos#long,5.32333) som fortel oss at lengdegraden til Bryggen er 5,32333.
Dette gjer det mogleg å finne lokaliserte (primære) Wikipedia-artiklar. Men PediaCloud søkjer óg opp såkalla sekundærartiklar, dvs. artiklar som har ei RDFlenke til eller frå ein lokalisert artikkel. Eit eksempel på eit slikt RDF-trippel er (dbpedia:Bergen,dbpediaont:leaderName,dbpedia:Harald_Schjeledrup) der vi har brukt ein forenkla notasjon. Trippelet fortel at leiaren i Bergen er Harald Schjelderup. Sekundære artiklar treng ikkje vere lokalisert.
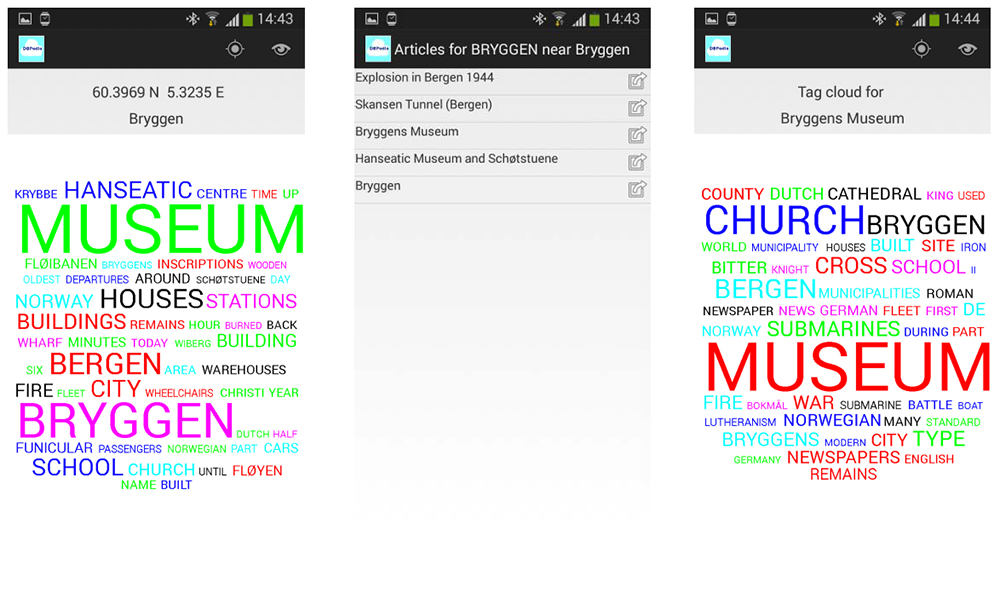
Alle primære og sekundære artiklar utgjer til saman eit lokalisert korpus av samandrag av Wikipedia-artiklar som vidare er grunnlaget for å danne ei ordsky (Rivadeneira et al, 2007). Artiklane får så vekt etter avstand frå brukaren og om dei er sekundære eller primære. For kvart ord i korpuset finn vi eit total vekt basert på artikkelvektene frå artiklar der ordet førekjem og tal på førekomstar av ordet. Figur 1 viser ein sekvens av skjermbilete frå PediaCloud for ein brukar som oppheld seg på Bryggen i Bergen.
Skjermbiletet til høgre viser ei ordsky som er danna av at ein lar ein artikkel i Wikipedia bli den «sentrale» artikkelen og vidare vektlegger andre artiklar i korpuset ut frå kor like dei er til denne valde artikkelen. Det gjev ei ordsky der ord får andre vekter enn for den lokaliserte ordskya.
I ei brukarevaluering av PediaClou i London i 2014 fann vi at brukarane var gjennomgåande positive til appen. Det som først og fremst kjenneteikna funksjonaliteten frå ein brukarståstad var at brukarane fikk ny, uventa og gjerne spennande kunnskap om ein stad (Tessem, Bjørnestad, Chen & Nyre, 2015). Som søkemekanisme kan vi kalle PediaCloud ein form for lukketreffsøk (engelsk: serendipitous search, Foster et al., 2003), der ein finn informasjon som i utgangspunktet ikkje var venta, men som likevel har nytte. Ideen passar óg godt inn i omgrepet «eksplorative søk» (Marchionini, 2006).
Kontekst og motivasjon for skynytt
Mediehusa i Noreg må tilpasse seg til journalistikk som vert presentert på nett og mobil. Heilt sidan Veven vart vanleg blant folk på 1990talet har avisene og deira journalistikk vore utsett for eit sterkt innovasjonspress. Nettaviser, gratis journalistikk frå ein overflod av tilbydarar, og nye deloffentlegheiter på Twitter og Facebook, tvinger avisene til å innovere for å nå lesarane, i Noreg og internasjonalt (Newman et al. , 2016).
Det vert laga mykje journalistikk for nett og mobil, men det er vanskeleg å tene pengar på den. Dei tradisjonelle mediehusa får derfor lågare inntekter ettersom folk sine lesevanar vender seg bort frå papiravisa. Det har vore fleire rundar med oppseiingar i norske mediehus dei siste 5-10 åra, og staben har skrumpa inn. Sjøvaag (2014) viser at medieselskapet Schibsted sette i gang kostnadsreduserande tiltak i 2012 som inkluderer nedmanning, innhaldssyndikering og sentralisering av kjernetenester. Det er ein trend at redaksjonane vert mindre, og at store konsern dominerer, med sine sentraliserte digitale produksjonslinjer for alt frå tekstarbeid til layout og redigering.
Men likevel er det altså slik at Noreg ikkje er i front når det gjeld innovasjon og teknologiutvikling i mediebransjen. Sørensen (2010) skriv om ei spenning mellom forsking og industri i Noreg etter 1945, og peiker på at næringslivet i Noreg er blitt kortsiktig og lite risikovillig. Med slike perspektiv på innovasjon har ikkje dei tradisjonelle avisene særleg mykje muligheiter for nyskaping i ein økonomisk pressa kvardag. I tillegg blir dei haldne tilbake av ei konservativ holdning blant journalistane. Ekdale et.al. (2015) fann ut at «dei som trur jobbane deira er i faresonen neppe kjem til å endre sin praksis», men fortsetje å dyrke den redaksjonelle profesjonaliteten dei har. Uvissa kring jobbar i nyheitsbransjen avgrensar omfanget av kreative endringar i den journalistiske praksisen (Ibid.). Westlund & Krumsvik (2014) finn den same typen avgrensande handlingar. Dei hevdar at redaksjonen og salsavdelinga vert oppfatta som mindre interessert i digital innovasjonsarbeid enn kollegaene deira i IT-avdelinga. Aviser og kringkastarar av den tradisjonelle typen endrar seg ofte for sakte for deira eige beste (Ruud 2014: 19), og dette opnar opp for nye selskap som overtek dominansen på ulike felt til dømes YouTube i videosamanheng og Facebook i nyheitssamanheng. Frå informasjonssystemforskinga ser vi at desse funna matchar godt med Hirschheim og Newmans (1988) analyser av ny informasjonsteknologi og motstand hos brukarane, der dei identifiserer eit 10-tals årsakar som blant anna inkluderer innebygd konservatisme, manglande følt behov, usikkerheit (knytt til jobb), manglande involvering, manglande tilpassing til organisasjonen og dårlege løysingar.
Samfunnsforskarar og økonomar følgjer godt med på det som skjer i mediebransjen. Dei siste ti åra har disiplinen medieinnovasjon vakse fram, og den studerer særleg forretningsmodeller og ulike casestudium av dramatiske endringar i marknader. Storsul og Krumsvik (2013) (red) presenterer feltet breitt, og det finst óg meir spesialiserte antologiar om innovasjon i lokale medier (Morlandstø og Krumsvik (red) 2014), entreprenørskap (Ruud 2014) og journalistikkfaget (Gynnild 2013). Denne disiplinen tek høgde for at nye teknologiar kan fungere «disruptivt» på journalistikken, og spør seg kva slags forretningsmodellar som fungerer best i framtida.
Designvitskap (innan informasjonssystemforsking) handlar hovudsakleg om å designe prototypar for teknologi som skal handtere reelle problemstillingar i verksemder (Hevner & Chatterjee, 2010). Ei designvitskapleg tilnærming til mediebransjens innovasjonsutfordringar vil potensielt kunne gje nye teknologiske løysingar av god kvalitet, samstundes som evalueringar i verksemder og blant brukarar vil kunne gje løysingane legitimitet. Designvitskapleg forsking vert gjerne finansiert og drive fram utanfor media eller kun delvis av media, medan løysingane som vert utvikla har ein større sjanse for aksept når dei er evaluert og vidareutvikla i samspel med verksemdene. Designvitskap høyrer derfor med blant verktøya som ein må kunne bruke i medieinnovasjonsfeltet.
Alt i alt gjev dette oss ein fleirfasettert motivasjon for prosjektet. Hovudsakleg ønskjer vi ei forståing for utviklinga teknologien som vert brukt i Skynytt. Dette inneber å utvikle teknologi som tek i bruk lokasjonar, ordskyer og informasjonsgjenfinningsteknologi for å leie lesarar til innhald i aviser. Vidare har vi óg eit ønskje om å forstå kva for perspektiv ei medieverksemd vil ha på denne teknologien og om den kan vere eit tilskot til innovasjonen i verksemda. Til slutt vil dette gje oss ei ny erfaring kring bruken av designvitskap som metode i medieinnovasjon, med ei betre forståing av korleis samspelet med mediebransjen kan utviklast. Dette siste poenget vert ikkje drøfta vidare i denne artikkelen, då vi treng meir data og analyser for konklusjonar rundt dette.
Systemet
Den nye versjonen av PediaCloud, altså kalla Skynytt, måtte tilpassast den type data vi har når vi snakkar om eit aviskorpus. I slike korpus er ikkje artiklane geotagga, dei har ikkje RDF-lenker til artiklar med nærskylde tema, og dataa fins ikkje i ein ferdig tilrettelagt database som DBpedia. Vi måtte derfor utvikle alternative løysingar for:
1. Lokalisering av artiklar
2. Lenking til artiklar som er like
3. Strategi for å lage ordsky basert på ein sentral artikkel
4. Lagring av artiklar og tilhøyrande metadata
I det følgjande skildrar vi korleis dette vart gjort.
Skynytts database
All informasjonen som vert vist i Skynytt-appen kjem frå ein dedikert database designa for formålet. I denne databasen lagrar vi artiklar frå Bergens Tidendes digitale arkiv. Dette inkluderer titlar, tekst, weburl, dato, forfattar og nyheitskategori. I tillegg lagrar databasen namn og koordinatar for lokasjonar i Bergensområdet. Desse er henta frå Google Maps Geocoding API (3) og opne data frå Statkart (4). Koplinga mellom artiklar og lokasjonar vart funne ved ulike heuristikkar implementert i algoritmar som gjennomgjekk kvar relevant artikkeltekst. Vi har fokusert på artiklar som handlar om saker innanfor Bergen kommune i perioden 2012 til 2015, og har i alt 21.212 unike artiklar, der 5.867 er geotagga med ein eller fleire av 567 unike lokasjonar. I tillegg har vi for kvar artikkel rekna ut og lagra referansar til dei 30 andre artiklane i korpuset som liknar mest, basert på informasjonsgjenfinningsteknikkar.
Geotagging av artiklar
Alle utrekningar knytt til geotagging må gjerast på førehand og resultata lagrast i databasen. Dette ville vore umulig å handtere for Skynytt-appen i seg sjølv. Algoritmen for å geotagge artiklar har fire overordna steg:
1. Isolér alle termar i teksten
2. Finn kandidattermar som potensielt kan vere lokasjonar
3. Søk etter lokasjonar i lokasjonsdatabasane basert på kandidattermane
4. Lagre oppdaga lenker mellom artikkelen og lokasjonar
Normalt er alle ord å rekne som ein term i steg 1. Det einaste unntaket er sekvensar av ord med stor forbokstav. Ein slik sekvens vert i denne algoritmen sett på som ein term. For eksempel, «han et» og «David et» vert rekna som to termar, medan «David Edward Henry Rollins III» vert sett på som ein term. Dette går som regel bra, men i enkelte tilfelle vil det bli problematisk der ein har stadnamn med fleire ord, men der berre det første har stor forbokstav, t.d. «Danmarks plass». Identifikasjon av namn i tekster har vore studert av fleire, og maskinlæringsløysingar som fungerer godt for norske tekster fins (Johansen, 2015), men vi har valt å bruke eit enklare system for dette.
Steg 2 er óg sentrert rundt ord med store forbokstavar. Sidan vi berre er interessert i namngjevne lokasjonar, ser vi berre på termar med stor forbokstav. Vi har då igjen, i hovudsak, fire typar termar: a) stadnamn (inkludert gatenamn), b) namn på organisasjonar, forretningar eller offentlege institusjonar c) personnamn og d) ord som tilfeldigvis hamna først i ei setning. Vi er berre interessert i dei to første, ettersom det berre er desse som kan koplast til geografiske lokasjonar.
For å eliminere den tredje kategorien, søkjer algoritmen gjennom dei 1.000 vanlegaste fornamna i Noreg for kvart kjønn. Dersom det første ordet i termen samsvarar med eitt av desse namna, og termen ikkje direkte vert følgt av eit ord som indikerer at det er namnet på ei gate (t.d. «veg» eller «gate»), vert termen ikkje tatt omsyn til. I tillegg, dersom termen inneheld fleire ord, vert alle termar i heile teksten som har førekomstar av eitt eller fleire ord frå denne termen óg fjerna. Dette er for å unngå problem der ein person er innført i ein artikkel med fullt namn, men seinare berre er referert til med etternamnet. Dersom dette etternamnet tilfeldigvis óg er namnet på ein stad som har relevans til artikkelen vil vi altså kunne få feilaktig geotagging. For å eliminere den fjerde typen termar, sjekkar algoritmen kvar term mot dei 10.000 mest brukte orda i norsk. Dette fjernar ikkje alle irrelevante ord for vurdering, men dei aller fleste. Dei resterande tilfella vert eliminert med at algoritmen normalt ikkje vil finne stader med namn som er identisk med desse meir obskure orda.
Trinn 3 inneber å søkje etter kandidattermane i to ulike datasett. Det første settet er alle registrerte stadnamn i Bergen kommune gjevne av Statkart. Resultatet av søket i dette settet kan vurderast som svært påliteleg og robust, mest av alt fordi settet berre inneheld namn på stader (den første, og minst fleirtydige av dei fire termkategoriane). Stadane som vert funne gjennom søk her er derfor veldig treffande, men må sjåast på som ufullstendig, sidan datasettet ikkje inneheld korkje gatenamn eller namn på bygningar. For å utvide resultatsettet, søkte vi derfor óg gjennom geokodings-API-et frå Google Maps. Dette søket gjev meir detaljerte resultat, men er mykje meir utsett for feil. Vi får dei stadene vi mangla i det første søket (namn på gater, bygningar, organisasjonar og verksemder), men det gjev óg stader for ord som ikkje er geografiske punkter i det heile tatt. For å redusere dette problemet, har vi berre lagra koordinatar i Bergensområdet. Utover Statkart og Google sine databasar er GeoNames (5) ei open kjelde til stadnamn basert på frivillig registrering. Den har enno for lite data til at den er relevant for oss å bruke. Den endelege lista av relevante stadnamn vart til slutt óg kontrollert manuelt for å fjerne opplagt feilaktige stader.
Det siste trinnet i geotagginga er å opprette koplinga mellom det geografiske punktet (med namn, breddegrad og lengdegrad) og artikkelen, og lagre denne i databasen. I sjølve appen brukar ein spørjingar mot databasen basert på ein posisjon henta frå mobilens posisjonssensor (GPS). Distansar frå gpslokasjonen til kvar artikkel vert rekna ut og utrekna avstandar mindre enn 150 meter vert deretter brukt av appen som kriterium for å velje artiklar nær posisjonen til brukaren. I appen får alle artiklar ei vekt (mellom 0,0 og 1,0) basert på distansen mellom brukaren og geotaggen til artikkelen. Artiklar over og på 150 meters avstand har vekt 0,0, og artiklar på identisk lokasjon får vekt 1,0. Denne vekta avgjer igjen i kor stor grad artikkelen bidreg i ordskya.
Utrekning av likskap mellom artiklar
I tillegg til søkefunksjon basert på posisjon, er brukarane óg i stand til å søkje etter nytt innhald basert på ein interessant artikkel. Dette skil seg frå PediaCloud der ein berre brukar artiklane i det initielle artikkelkorpuset når ein skal endre fokus frå lokasjon til ein interessant artikkel. I Skynytt gjer ein kvar gong eit nytt søk mot databasen og kan såleis følgje assosiative lenker i større grad. Dette impliserer at vi i staden for geografisk plassering som grunnlag for søket, brukar sjølve tekstene for å finne nærskylde tekster. Vi brukar då ikkje romleg avstand mellom artiklar til å rekne ut vekter, men heller ein semantisk avstand. Vi har derfor identifisert ein metode for å samanlikne artiklar basert på tekstleg innhald og returnere eit mål på likskap mellom 0 og 1. Vi kallar denne typen søk for eit assosiativt søk.
Desse utrekningane vart, som med geotagging, utført av ekstern programvare, og berre resultatet av utrekningane er brukt i appen. Her brukar vi standardparametre frå informasjonsgjennfinningslitteraturen (Sjå for eksempel Manning et al., (2007)). Dette inkluderer invers dokumentfrekvens (IDF) for ein term, oftast gjeve ved 𝐼𝐷𝐹=ln(𝑁𝑑𝑓(𝑡)⁄)+1 der 𝑑𝑓(𝑡) er tal på dokument som inneheld termen t og N er totalt tal på dokument og termfrekvens (TFi,j) som indikerer kor mange gonger ein term ti førekjem i do-kument j. Effekten av IDF er at ord som førekjem veldig ofte i dokumentsamlinga ikkje får så stor vekt som term-frekvensen skulle tilsei, dvs. at meir signifikante ord tel meir. Cosinus-similaritet er eit stan-dardmål som brukar TF-IDF-scorar til å rekne ut kor like to dokument er. Dette gjerast ved å rekne ut TF-IDF-verdiar (i formelen under gjeve som 𝑤𝑖,𝑗) for kvart ord i kvar artikkel (𝑤𝑖,𝑗=𝑇𝐹𝑖,𝑗/𝐼𝐷𝐹𝑖 der 𝑇𝐹𝑖,𝑗 er term-frekvens for term ti i dokument dj og IDFi er invers dokumentfrekvens for term ti). Vi får då cosinus-similariteten til to dokument som:
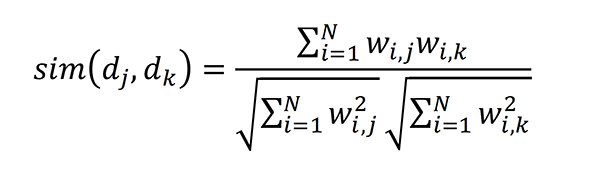
Artikkel-samanliknaren tar heile artikkelsamlinga og reknar ut likskap mellom alle par av artiklar i tre trinn:
1. Hent ut alle ord og generer ein IDF-verdi for alle ord.
2. For kvart par av artiklar.
a. Lag ei liste over alle ord brukt i ein eller begge artiklane med tilhøyrande termfrekvensverdiar.
b. Rekn ut TF-IDF-verdiar for alle ord i begge artiklane.
c. Rekn ut cosinussimilaritet mellom dei to listene med TF-IDF-verdiar basert på formelen over.
3. For kvar artikkel: Lagre referansar til dei tretti mest liknande artiklane i databasen.
Trinn 1 gav for dagens artikkelsett 213.697 unike ord, og kvart av desse orda vart tildelt ein IDF-verdi. Eit ord som er til stade i kvar artikkel vil få IDF-verdien 1.0, medan eit ord som er i ein av artiklane får ein IDF-verdi nær 11. Med det eksisterande artikkelsettet spenner verdiane frå 1,005 (for ordet «i») til 10,959 (alle ord som førekjem ein gong i artikkelsamlinga).
I trinn 2 reknar vi ut cosinussimilariteten mellom kvart par av artiklar. Dette blir eit tal i intervallet [0,1] der verdien 0 indikerer ingen identiske ord (termar), medan verdien 1 indikerer eksakt same tal på ord for kvart einaste ord.
Det vil vere for plasskrevjande og ikkje i utgangspunktet nyttig for appen å lagre informasjon om likskapen mellom alle par av artiklar. Når ein brukar vel å fokusere på ein artikkel og ønskjer å finne nærskylde artiklar til den burde 30 artiklar i utgangspunktet vere eit rikeleg utval. Derfor har vi valt å lagre referansar til dei 30 mest liknande andre artiklane for kvar artikkel saman med cosinussimilariteten. Cosinussimilariteten vert óg brukt til å vektlegge artiklar i utrekninga av ordskya. Cosinussimilariteten fungerer altså på same måten som vekta som kjem frå lokasjonen når vi reknar ut ordskya, som forklart i seksjon 3.2.
Vekting av tid
I den versjonen av Skynytt som er presentert i figurane her, er vi i stand til å vekte kvar artikkel, ikkje berre lokasjonbasert, alternativt på cosinussimilaritet, men óg på tid. Det vil sei, at den frå før utrekna vekta til artikkelen vert multiplisert med et tal mellom 0 og 1, basert på tal på dagar mellom artikkelens dato og ein vald dato.
I søket kan brukaren velje mellom fire ulike datoar: 15 juni i eit av åra 2012, 2013, 2014 eller 2015 (2015 er sett som standardverdi). I det assosiative søket der ein søker etter nærskylde artiklar, gjev appen vekter basert på publiseringsdato, dvs. at artiklar som har høg cosinussimilaritet og er nær i tid får høgare vekt. Om brukaren vel eit av årstala i appen (sjå Figur 2), vil tidsmessig nærleik til den tilhøyrande datoen påverke artiklane sine vekter. For eksempel kan brukaren velje (15. juni) 2015 for å gje meir vekt til nyare artiklar. Skynytt kan altså i denne prototypen handtere nokre få utvalde datoar som input til ei datovektingsalgoritme.
Datovektfunksjonen er ein funksjon som gjev ein verdi i intervallet [0,1]. Den er i dag implementert som 𝑓(𝑑𝑖,𝑑𝑗)= 150(|𝑡𝑖−𝑡𝑗|+150) der 𝑑𝑖 er dokument i og 𝑡𝑖 er publikasjonsdatoen for 𝑑𝑖. Dette gjev ein funksjon som smalnar raskt av til 0,5 etter 150 dagars forskjell, før den går sakte ned mot 0. Størst mulig gap mellom datoar i det aktuelle datasettet finn ein rundt 1.500 dagar. Dette vil gi ei datovekt på omlag 0,1. Ein artikkel innan ein månad av fokusdato vil få rundt åtte gongar høgare vekt enn ein tre år frå. Denne funksjonen gjev eit fokusområde på ca. tre månader på kvar side av den aktuelle datoen som gjev merkbart meir favoriserte artiklar, og bidrar til år-til-år-forskjellar som er lett å få auge på i ordskyene.
Optimalt bør brukaren kunne plukke ein søkedato fritt frå eit kontinuum når det vert utført eit assosiativt søk. Men ein må då handtere artiklar som både er nær i tid og lokasjon, eventuelt tid og innhald (cosinussimilaritet) og ha strategiar for å handtere kombinasjonar av desse kriteria for å finne dei best matchande artiklane. Dette er ikkje trivielt, og vil for eksempel bety at dei 30 mest like artiklane etter cosinussimilaritet ofte ikkje vil vere tilstrekkeleg for å få gode resultat i eit assosiativt søk, sidan dei 30 artiklane kan vere spreidd i tid og nokre dermed bli irrelevante dersom ein tek omsyn til tid.
Dette kan gå greitt om ein ved kvar assosiasjon vel artikkeldatoen som utgangspunkt for tidspunkt, då kan vi bruke eit avgrensa sett (for eksempel 30 artiklar) som vert scora både etter similaritet og tid. Men de vert vanskelegare om brukaren vil ha fokus på andre datoar. Vi har enno ikkje tatt fatt på ei vurdering av korleis dette kan handterast, men det kan eventuelt gjerast med at ein frå similaritetsutrekningane hugsar fleire artiklar frå kvart år for å få eit tidsspenn. Desse kan vere fordelt ulikt med flest nærskylde artiklar frå året rundt publikasjonsdato og færrast frå år som ligg langt vekke tid. Alternativt kan ein velje å lagre alle similaritetsutrekningar. Men vi har ikkje slik det er no, tilgang til datamaskinressursar til å lagre og effektivt søke i similaritetar mellom alle par av artiklar (i dag ei matrise med i underkant av 450 millionar similaritetsmål).
Skynytt-appen
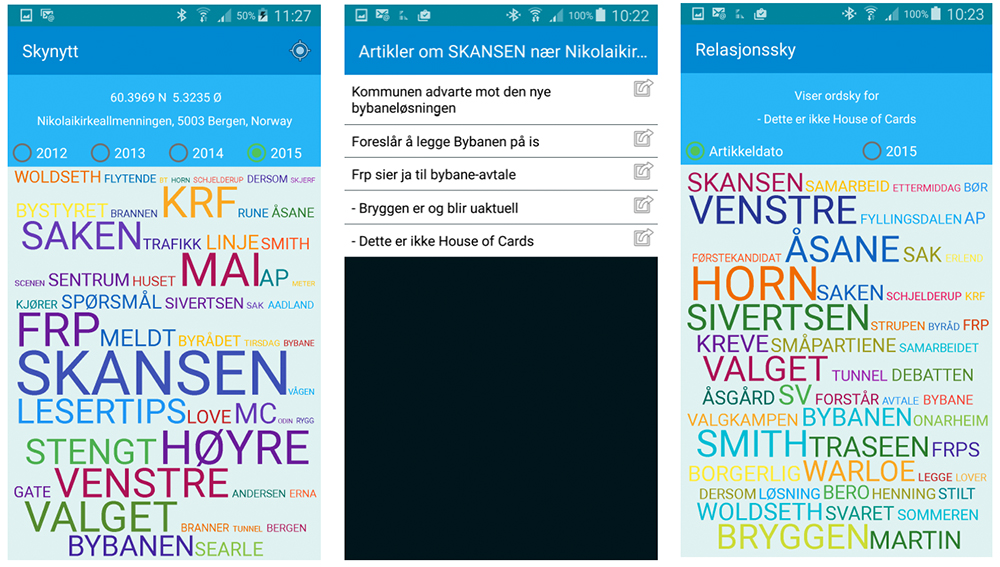
I Figur 2 ser vi Skynytt slik den viser ei ordsky for 2015 på Bryggen i Bergen. Den viser tre skjermbilde som brukarane vil kunne sjå på den plassen. Dette var på ei tid då diskusjonane om lokalisering av Bybanen i Bergen gjekk høgt, og namn på politikarar dukka opp som viktige ord. Til dømes referer «SKANSEN» til politikaren Dag Skansen frå partiet Høgre. Fem artiklar viser seg når vi trykker på SKANSEN og vi vel vidare å fokusere på artikkelen med tittel « Dette er ikkje House of Cards» (assosiativt søk) og viser ordskya for den artikkelen med vektlegging av dei artiklane som ligg rundt artikkeldatoen. I denne ordskya viser det seg at andre politikarnamn, som «HORN» som refererer til Erlend Horn frå partiet Venstre, får høgare vekt.
Metode
I dette forskingsprosjektet følgjer vi ei klassisk designvitskapstilnærming (Hevner & Chatterjee, 2010) der vi utviklar ein prototype, ofte kalla artefakt, og evaluerer den etter ulike kriterier. Hevner et al. (2004) nemner ein del viktige retningslinjer for designvitskap. Først og fremst må ein faktisk designe ein artefakt som relaterer seg til eit reelt verksemdsproblem. Så må ein utføre ei evaluering som saman med artefakten bidreg til ny kunnskap om design i seg sjølv. Målet med evalueringa er ofte å få kunnskap som hjelper oss i eit søk etter betre løysingar. Vitskapleg soliditet og forskingskommunikasjon til forskarar og verksemder er óg sentrale i eit designvitskapleg prosjekt. Motivasjon for dette prosjektet og designet av artefakten har vi allereie gått gjennom i seksjon 2 og 3, medan dei resterande retningslinjene for designvitskap er i fokus i resten av artikkelen.
Når det gjeld evaluering har vi allereie testa ut ein liknande teknologi for brukarar av informasjonstenester gjennom vår undersøking i London i 2014 (Tessem et al., 2015). Vi meiner at dei brukaroppfatningane vi der fann på ei ordsky og lokasjonsbasert informasjonsteneste truleg vil la seg direkte overføre til ei nyheitsteneste. Det vi enno ikkje har innsikt i er korleis avisverksemda og dei som skal lage innhald vil oppfatte denne teknologien, og om det kan vere nytte i dette for verksemda.
Sidan teknologien enno er relativt uferdig har vi valt å sjå på evalueringa som ei slags formativ studie der vi hentar inntrykk frå eit avgrensa tal av respondentar og vidare vil bruke dette til å eventuelt vidareutvikle konseptet. Enno er ikkje teknologien klar for å setjast i produksjon og det vil krevjast mykje vidare innsats for at ein skal få sjå slike ordskyer blant avisenes tenester. Resultata frå evalueringa var tenkt avdekke om vidare utvikling er ønskjeleg og korleis ein eventuelt skal fokusere forbetring av designet.
Vi intervjua fem tilsette i Bergens Tidende, tre journalistar, ein redaktør og ein marknadskonsulent. Intervjua føregjekk i kontora til Bergens Tidende i same veka i juni. Vi meiner at vi med dette utvalet av respondentar fekk ei brei og tilstrekkeleg gruppe av interessentar frå inne i verksemda som óg var nyttige på dette tidspunktet i forskingsprosjektet.
Respondentane fekk leike litt med appen og prøvde ut funksjonaliteten som den er presentert i Figur 2. Her hadde det kunne vore fint om respondentane i staden fikk bruke appen for eksempel i ei veke på eige utstyr. Det ville vore problematisk av to årsakar. Den eine er ganske triviell, knytt til kva mobiltelefonar respondentane har. Appen er utvikla for Android-telefonar og ein versjon for iPhone-telefonar fins ikkje.
Den andre er at journalistar lever i ein travel og ustrukturert kvardag og vi hadde risikert at appen ville vore ubrukt når dagen for intervjuet kom. Alt i alt vart det derfor enklare for oss å gå gjennom bruken i intervjulokalet og svare på eventuelle omkring brukaropplevinga der og då.
Etter at respondentane hadde prøvd appen gjennomførte vi eit semistrukturert kvalitativt intervju der vi gjekk gjennom tema som inntrykk av appen, bruk av ordsky, bruk av tidspunkt i søket, journalistisk potensiale for lokasjonsbaserte nyheiter, verdi i høve til arkivet og marknadspotensiale. Respondentane vart informert om at alle svara og oppfatningane ville bli anonymiserte.
Analyse
Analysen av fokuserer på generelle inntrykk av appen, oppfatningar av ordskya, muligheiter i journalistikken, gjenbruk av arkivet og marknadspotensiale for denne teknologien.
Inntrykk av appen
I utgangspunktet var respondentane nysgjerrige i høve til appen, og responsen varierte frå overstrøymande positiv til noko kritisk.
«dette er jo helt gull, jeg bare tenker at, altså, det er jo kjempespennende.»
«Fiffig er det første ordet som slår meg med dette, også sitter jeg igjen med den følelsen: ”Hva gir dette meg som leser?”»
Dei forstod at den var ein prototype, og karakteriserte den likevel som «heimesnekra». For at dei skulle kunne presentere dette til brukarar treng vil ein måtte forbetre det visuelle og brukargrensesnittet. Dei forstod likevel konseptet godt, sjølv om ikkje alle delar vart oppfatta som like intuitivt. Dei reflekterte etter kvart godt om korleis slik teknologi kan nyttast. Dei nemner turistar, skuleelevar og studentar som brukarar av lokasjonsteknologi generelt. Ein ide som var ny var at bustadkjøparar nytte av ei slik teneste. Dette var nemnt av fleire:
«Det var liksom et ganske morbid drap som skjedde på 80-tallet, som skjedde tjue meter fra døren min. Sant, og det er jo kanskje en vinner på visning, men det er sånn ting som du er interessert i, for du er interessert i ting som skjer rundt deg da. Og det tror jeg er veldig interessant.»
Tilrettelegging av tenesta var óg eit tema dei diskuterte. Fleire meinte at den måtte i tilfelle vere plassert som ein funksjon menyen på mobilappen eller mobilutgåva til Bergens Tidende, sjølv om ein óg kunne tenke den som ein eigen app.
«Man kan tenke seg at den er en hybrid som er et tilbud til alle, det blir en sånn ”Utforsk Bergen”del av det sant, flytter du til Bergen eller, hva skjedde i nabolaget sant, det er ikke sikkert du får lese alle sakene, men du får i alle fall oversikten over hva sakene handler om.»
Óg når det gjaldt brukarvenlegheit fikk vi mange kommentarar. Det gjekk på slikt som fargeval, forklaring til brukarane, og brot med forventningar til korleis ting skulle vere. For eksempel er det slik at ordskya vert teikna på nytt kvar gong ein går tilbake til ei tidlegare ordsky. Sidan dette er ein tilfeldig prosess, betyr dette at orda flyttar seg og får nye fargar, sjølv om det er dei same orda. Dette reagerte ein av brukarane på:
«Det var egentlig bare det at det ordet som jeg prøvde å trykke på som jeg ikke trykket på, ville jeg kanskje prøve å trykke på når jeg kom tilbake igjen, når jeg hadde lest det. Og da fant jeg ikke det igjen, for det var ikke et stort ord sant.»
Det vart óg reagert på kor lite intuitivt det var å forstå at det fins ei ordsky for assosiativt søk knytt til artikkelen (denne ordskya har overskrift Relasjonsordsky i appen, Sjå Figur 2). Det var inga forklaring av dette og ikonet som var valt gav ingen hint om noko slikt:
«Så var det ganske, du måtte trykke her ute for å lage en ny ordsky, det var helt, rett og slett umulig å vite. Sånn som ikonbruken og sånn er nå.»
Dei syns at tilgangen til BT sitt materiale var altfor tilfeldig, og for lite styrt av brukarens behov. Dei ønskte for eksempel tematisering eller filtrering av innhaldet, slik at brukarane kunne gjere meir styrte val. Brukarmodellering er óg potensielt viktig. Ein kommenterte på at appen burde vite om dette var ein plass brukaren var ofte:
«hvis den i tillegg kan lese at dette er et sted som du ikke er så ofte, sant, om jeg får opp de samme anbefalingene når jeg står på busstoppet hver morgen så er jo det ganske irriterende»
Eit anna potensiale i appen (og generelt i lokasjonteknologi for nyheiter) er at den kanskje kunne ha bygd inn funksjonalitet som oppsummerte nyheitene i området:
«Det er mer for å raskt sette seg inn i den lokasjonen du er på. Og derfor tenker jeg at det hadde vært utrolig kult hvis dere hadde fått til sånn oppsummerende.»
Eit viktig funn frå brukarundersøkinga av PediaCloudversjonen var funnvedlukketrefffenomenet. Vi fann nokre eksempel på dette i dataa frå BT-tilsette. Dei intervjua vart som brukarar overraska over kva som dukka opp på ulike ord, noko som vekte interesse. Ein av brukarane trykte på «BARN» og fikk opp lenker til ein artikkel om Monika-saka (drap på ei 8 år gammal jente frå Litauen).
«det er jo litt interessant da, for dette er jo hun Sviglinskaja, det er jo den Monika-saken. Men hvordan er de relatert? Det må jeg jo bare se»
Det er interessant at vi fikk sjå denne effekten allereie etter nokre få minutts bruk av appen.
Ordskya
Som sagt så vart ordskya oppfatta som noko primitiv. Brukarane forstod heller ikkje heilt korleis lokasjon fungerte i høve til ordsky, nemleg at ord i nærliggande artiklar gjerne fikk større vekt. Ein av respondentane hadde erfaring med bruk av ordskyer i ein annan samanheng og meinte at vår løysing kunne vere forvirrande, men aksepterte forklaringa om at nærleik til lokasjon kunne vere eit anna kriterium for storleik. Dei kommenterte óg utvalet av ord og det kom fram at utvalet av ord gjerne kunne vore meir fokusert, slik at ord frå artiklane i større grad reflekterte tema og vinkling i artikkelen. Slik det er no verka orda heilt tilfeldige.
Når det gjeld ordskya som inngang til lokasjonsbasert informasjon hadde ein eit ganske klart standpunkt om at ordsky ikkje fungerte:
«en ordsky gir ikke meg en følelse av stedsbasert tjeneste, så jeg får ikke helt frem hva dette er for noe, sånn intuitivt.»
Men óg her har vi motstridande data. Ein av respondentane som er meir positiv til ordskya som inngang til lokaliserte artiklar er svært kritisk til kart som søkeverktøy og ser det meir som eit verktøy for illustrasjon:
«Dette har vi jobbet mye med, kart som navigasjon på mobil, forferdelig. Nesten bøtte umulig. Veldig vanskelig å bruke. Vi har brukt mye tid på det, det er forferdelig vanskelig å bruke som navigasjonsform. Illustrasjonsform? Perfekt.»
Journalistisk potensiale
Avisa har allereie ein del løysingar som er lokasjonsbaserte. For eksempel ved at folk kan velje område på kart og få tematisk informasjon om det området, eksempelvis om skular. Interessant er det óg at journalistane bruker verktøy som finn ut kvar tilfeldige folk er ved å kikke på sosiale medium som Twitter og Facebook, og basert på dette ringer dei opp og ber dei om å ta bilete frå stader med viktige hendingar. Ei trafikkteneste vart óg nemnt som noko dei jobba med å utvikle. Ein meir generell bruk av lokasjonsteknologi som respondentane kan tenke seg er å identifisere område som har fått lite eller stor dekning i den siste tida og brukast til å endre fokus for journalistikken.
Når det gjeld Skynytt-funksjonaliteten, følte ein del av respondentane at ein slik app i stor grad ville bryte med avisas rolle som ei redigert framstilling av omgjevnadane. Ved ei slik tilfeldig presentasjon av innhald der brukaren sjølv får velje, vil avisa miste ein av sine viktigaste kvalitetar, nemleg ansvaret for å fokusere på tidsrelevante og viktige nyheiter. Aktualitet og nyheitsverdi skal ha førsteprioritet for det ein presenterer for lesarane, men det vert opna for ein kombinasjon:
«Vi må kombinere det vi vet om hva de leser, og kombinere det med det vi mener at de bør lese. Så at vi ikke gir glipp på den dimensjonen ved det. For det er jo, jeg synes det er en livsfarlig utvikling hvis du overlater alt til det folk foretrekker, da kommer våre lesere til å bygge sine egne lesemønstre og vi kommer til å i langt mindre grad nå ut med den journalistikken vi mener er vesentlig, så det er et ganske viktig slag. Så gir vi slipp på den redigerte presentasjonen av virkeligheten, bare åpner opp for at det du er opptatt av er det du skal få, det har litt sånn overordnede konsekvenser over tid da.»
I den grad ein kunne inkludere den i innhaldet vart ein slik teknologi heller oppfatta som noko som kunne gje ein rikare presentasjon for lesaren:
«i stedet for å lage et produkt som på en måte altså står på egne bein da, så kanskje dette kunne vært brukt som en del av noen annet også, som en berikelse? Lokasjon er jo noe som vi ikke har brukt i det hele tatt.»
Geotagging og anna tagging av innhaldet frå journalistane si side er opplagt noko som kunne gjort ordskyer meir treffande som søkeverktøy og det er alle innforstått med. Men dei uttrykte ulike grad av skepsis til tagging av innhald. Nokre tenkjer på journalistens arbeidspress og at tagging vil vere ei ny arbeidsoppgåve, medan andre meinte at tagging allereie var så viktig for søkbarheit at dei meinte at dette burde innarbeidast i praksis så fort råd:
«for å få det til å skje er jo blant annet noe så banalt som tagging, tagging er fremdeles noe som er omdiskutert blant journalister i bedriften, og det er hårreisende. De har ikke skjønt hva vi holder på med. Det er jo helt nødvendig for at vi skal kunne lage tjenester. Og i en sånn tjeneste som den ordskyen sant, tenk hvis taggene hadde vært der. Hvis journalister faktisk hadde røktet det innholdet sitt, og det lå to-tre tagger minst på hvert innhold, da du hadde fått en mye, mye bedre sånn ordskyting sant, for da kunne du ta utgangspunkt i kurerte tagger i stedet for en algoritme.»
Gjenbruk av arkivet
Arkivsøk og tenester som gjev tilgang til arkivet vert vurdert som nyttige av respondentane, sjølv om dei uttrykte misnøye med søkefunksjonen som lesarane har tilgang til i dag. Arkivet er mest tilrettelagt som verktøy for journalistar. Nokre la vekt på at arkivet er ein interessant ressurs som ein óg kan ha glede av som lesar, ikkje berre som journalist.
«Google har bare skjønt, de har en veldig ekstrem forståelse av at mennesker er ubrukelige sant, de legger det til rette for det, de har jo skjønt at du må ha hjelp. Og det må medieorganisasjonene skjønne og, folk må ha hjelp da, til å gjenoppleve innhold og få frem igjen innhold. Og da kan du tenke sånn, for fem år siden skjedde, la oss si at du går inn på den appen på en gitt dato, så har du da en ordsky, eller skjedde det noe vesentlig 5, 10, 15, 20, 25, 30 år siden innenfor den uken? Og så får du opp da, sånn som Isdalskvinnen sant, du går forbi Svartediket og så ser du: ”skjedde det noe her?”. Ja, faktisk, for 30 år siden så, eller for mer»
Skynytt vil jo óg kunne bidra her sidan ein får tilgang til innhald som ein elles aldri ville lest eller funne ut. I det heile vert ein tidsdimensjon på innhaldet slik det er realisert i ein av versjonane av Skynytt sett på som positiv, men den må vere mykje meir fleksibel enn det årstalsvalet som er implementert i prototypen. Ein av respondentane var svært opptatt av arkivet som ressurs og kunne tenkje seg å kombinere andre visuelle teknikkar med ordskya for å få eit inntrykk av eit tidsspenn:
«Man kunne tenke seg sånn klassisk filter med søylegrafer sant, histogrammer, så bare drar du med sånn ”slider”, du får et inntrykk av hvor mye artikler er det på de ulike årene. For det kunne vært veldig gøy, for det er veldig interessevekkende, hva i all verden skjedde i 1997? Og det er jo måten vi ofte, det er jo sånn vi leser data på sant, typisk med årstall og sånne tidspunkt, så tar vi å strukturerer det bortover og ser på søyler, så tenker vi enten ”hvorfor er den søylen så høy?”, eller ”hvorfor er det egentlig her”, det er de to tingene som er interessante.»
Marknadspotensiale
Marknadsavdelinga brukar allereie i dag lokasjonsteknologi for annonsering i from av eit verktøy som styrer annonseringa etter IP-adresse. I tillegg brukar dei sosiale medium som Facebook til å presenter innhald for potensielle lesarar, men den funksjonaliteten er ikkje lokasjonsbasert. Når det gjeld Skynytt derimot stiller dei seg nokre spørsmål om nytten:
«Men når man er i gang med dette, hva er den overordnede tanken og visjonen med produktet? Hvilke behov skal det dekke? […] er det en nyttetjeneste eller en sånn gøy tjeneste?»
Men likevel hadde dei idear om den kommersielle verdien. Sponsing av lokasjonar eller liknande var det mange som nemnde:
«den kunne liksom laget områdesponsing eller appsponsing eller ordsponsing? Det er jo mange muligheter og jeg tror at det med reklame og kommersielt budskap vil hele tiden måtte prøve å finne nye veier.»
Men sponsingkonseptet er likevel problematisk sett frå journalistens synspunkt, og Vær Varsom-plakaten vart nemnt. Likevel, uavhengig av journalistisk kopling kan ein sei at denne typen teknologi kan skape eit potensiale for lokaliserte annonsar eller kopling av ei verksemd til ein plass. Slik annonsering måtte i tilfelle automatiserast, gjerne med budgjeving for å få tilgang på ein stad.
«det er jo sånn vi har begynt å selge annonseplassene våre programmatisk etter hvert sant, at du legger inn, du ønsker å nå en målgruppe sånn og sånn i det området, og jeg legger inn en pris jeg er villig til å betale for det, og hvis jeg har den beste prisen så får jeg den visningen sant. Men hvis noen byr høyere så får jeg den ikke. Sant, og det der er jo en sånn ”live bidding” som skjer. Så det finnes jo teknologi for det. Så du kunne jo sagt at hvis du hadde Zachariasbryggen eller Fisketorget eller Bryggen da som et område»
Verdien for ein annonsør kan potensielt vere ganske stor meiner ein respondent, men det gjeld å finne måtar å bygge opp ein slik hyperlokal annonseringsmodell.
Ingen trudde at ein kunne ta abonnentsbetaling for ei slik teneste. Sidan den mest er å oppfatte som kuriosa, vil brukarane ikkje ta bryet med betale for dette. Den vil kunne fungere som ein av mange gratistilbod som bidrar til å gjere avisa til ei rikare og meir interessant oppleving. Den kan slik sett fungere som eit tilbod som rekrutterer nye abonnentar:
«hvis den var en frittstående app på siden som ble tatt i bruk uavhengig om du var en BTleser eller ikke, så vil den være verdifull for oss i et leserperspektiv for å rekruttere lesere og et nytt sted som genererer nye lesere, ligger den inne hos oss så er den bare en del av det tjenestetilbudet vi har til allerede eksisterende lesere, og ikke gi noen flere brukere.»
Diskusjon
Dei fem intervjua gav oss mange innsikter om korleis Skynytt vert oppfatta blant tilsette i ei veksemd som eventuelt skal gjere seg nytte av denne teknologien. Dei skal produsere innhaldet, dei skal tilrettelegge for lokasjonssøk og dei skal få dette til å passe med ein framtidig inntektsmodell. Samtidig må ein spørje seg sjølv om fem tilsette i Bergens Tidende representerer ei for smal gruppe av interessentar til at ein kan få eit breitt inntrykk av kva nytteverdi Skynytt kan ha. Det er alltid ei utfordring som forskar å trekke konklusjonar omkring validitet, og i dette tilfellet er det interessante kontrastar i brukarstudiet av PediaCloud og innhaldsprodusentanes sine oppfatningar. Kanskje ville BT-respondentane hatt ei noko anna oppleving om dei óg fikk høve til å bruke appen i fleire dagar på vandring gjennom byen? Uansett ser vi ei klar nytte i funna. Dei gjev oss eit høve til å vurdere designet slik det er, samtidig som dei peiker ut framtidige vegar å forbetre konseptet.
Det vart peika på det visuelle designet som noko som ikkje ville fungere godt overfor kundar. Dette må forbetrast om dette skal kunne fungere som noko anna enn ein prototype. Det vart peika på utteikninga av ordskya sjølv, ikonbruk og kor intuitivt grensesnittet verka. Respondentane ville gjerne óg ha forklaringar på korleis ting fungerte som ein del av brukargrensesnittet. Responstida til løysinga var óg noko dei reagerte på, men dei var førebudd på dette, så dei kommenterte det ikkje i særleg grad.
Det ligg i heile ideen til Skynytt at ein utnyttar arkivet til å finne innhald. Endå betre muligheit til å kontrollere tidsdimensjonen i appen gjev brukarane betre kontroll over kva for innhald dei får tilgang til. Dette kan opplagt sjåast på som ei forbetring, og bør arbeidast med i ein ny versjon. Det er utfordringar med dette, knytt til vektlegging av tid i høve til lokasjon og i høve til det som skjer vidare i eit assosiativt søk.
Sjølve ordskya var ein viktig del av brukaropplevinga og ordutvalet vart sett på som for lite spesifikt eller konkret. Vi ser for oss at det vil vere eit utfordring å lage betre stoppordlister, for det kan vere vanskeleg å greie å identifisere dei orda som faktisk gjev mest eller minst meining på ein plass. Til dømes dukkar det gjerne opp generiske ord som «SAKEN» og «LEGGE» i ordskya. Dei kan vere viktige ein stad, men uvesentlege ein annan plass. Endå vanskelegare, men spennande utfordringar, vil det vere å generere korte fraser som fortel noko om plassen ved å samordne innhald frå artiklane og vidare å få dette tilpassa ein ordskypresentasjon.
Respondentane var opptatt av muligheiter for å kategorisere innhald, for eksempel i sjangrar som sport, kultur og nyheiter. Ein kan gjerne óg kople inn andre brukardata i utvalet av artiklar, og vektlegge artiklar som matchar ein bestemt brukarprofil høgare. Dette er teknologi som allereie vert brukt til å velje ut nettsider hos søkeportalar som Google og kan sikkert implementerast. Men samtidig er dette allereie veldig godt handtert i desse løysingane. Skynytt-opplevinga bør gjerne representere eit alternativ med sitt fokus på det eksplorative lukketreffsøket der fokus er mykje meir på lokasjon og i nokon grad på tid. Vi fann at respondentane faktisk opplevde lukketreffepisodar som i PediaCloud, men i deira analyse av teknologien vart ikkje dette sett på som spesielt viktig. Vi er usikre på om journalistanes perspektiv i denne samanhengen er rett. Det er ikkje alltid at brukarar finn ei teneste interessant på den måten som leverandøren tenkjer, og her avvik respondentane våre frå brukarane av PediaCloud.
Det vart nemnt av fleire at ein i staden for ordskya heller burde satse på interaktive kart eller noko så enkelt som lister av artiklar, sjølv om ein var kritisk til bruk av kart som hjelpemiddel i søk på mobilen. Dette er mulige forenklingar av Skynytt, men vil gje ei anna oppleving for brukarane. Ei oppleving som kanskje ikkje vil vektlegge overraskingselementet like mykje.
Bergens Tidende har i dag ikkje har eit godt system for temamerking og geotagging av artiklar, og for framtidige, meir avanserte versjonar av Skynytt synest det viktig at slik tagging faktisk vert utført. Det vart uttrykt skepsis til at journalistane skulle gjere dette. Om vi aksepterer det, vil vi måtte prøve ut endå meir avanserte algoritmar for automatisk lokalisering, innhaldsanalyse og kategorisering av artiklar. Noko som ville vere eit større forskingsprosjekt i seg sjølv.
Det er tydeleg at redaksjonen vil ha sterkare kontroll over prioritering av sakene som vert presentert for brukarane enn det som det er lagt opp til i Skynytt. Aviser ser det som si viktigaste oppgåve å produsere aktuelle og viktige nyheiter for lesarane, og dei vil styre lesarane mot det som er viktig i samfunnet i dag. Ein teknologi som gjer denne rolla mindre viktig vert med ein gong sett på som problematisk. Ein kan godt sjå på dette som eit eksempel på klassisk motvilje mot endringar i informasjonssystem (Hirschheim & Newman, 1988). Sjølv om pressa opplever eit konstant innovasjonspress, fins det ein innebygd konservatisme i høve til korleis nyheiter skal oppfattast, produserast og lesast. Det er óg ein redsel for auka arbeidspress i og med at ein får eit ansvar for å tagge artiklar. Kanskje aller viktigast er det at dei fryktar at slike verktøy kan svekke journalisten og redaktørens posisjon og makt.
Respondentane ser óg ut til å tenkje på lokaliserte nyheiter som noko mindre hyperlokalt enn vi har lagt til rette for i Skynytt. Dei tenkjer seg at brukarane skal få tilgang til nyheiter frå større område og dermed óg eit større tilfang av nyheiter. Dei tenderer til å meine at hyperlokal reklame vil kunne fungere betre i ein slik app enn den hyperlokale journalistikken. Kunden som er på staden er ofte veldig viktig å nå for verksemder som restaurantar og butikkar og gode modellar for kjøp av slik reklameplass kan utviklast. Men samspelet mellom journalistikk og reklameinnhald kan vere utfordrande ettersom begge deler må vere til stade for å få eit produkt som brukarane oppfattar som truverdig og interessant og som samtidig er inntektsbringande for avisa. I utviklinga av Skynytt og liknande tenester må ein bygge inn ein inntektsmodell som kan gjere nytte av den dynamikken vi får mellom lokasjon, nyheiter og lokale verksemder som treng kundar.
Konklusjon
Gjennom den evalueringa vi har fått gjennomgått her, ser vi klart eit potensiale for vidareutvikling av Skynytt. Den designvitskaplege evalueringa fungerer som ei formativ evaluering der vi har avdekka både svakheiter og muligheiter. Appen har eit uferdig preg når det gjeld brukaropplevinga, både når det gjeld overordna design og ordskya, men dette er noko som lar seg handtere dersom ein vel å fokusere på det. Viktigare er at ordskyideen i seg sjølv kan vere for lite treffsikker og gjev for lite informasjon til brukaren om kva som er interessant på ein lokasjon. Dette kan handterast med meir avanserte algoritmar for utval av ord og fraser og filtrering av innhald, noko som igjen krev grundigare utprøving av ulike former for informasjonsgjenfinningsteknologi. Dette vil inkludere naturleg språkgjenkjenning, naturleg språkgenerering, algoritmar for temaanalyse og teknologiar for automatisk merking av innhald.
Men evalueringa viser óg at denne typen teknologi ikkje nødvendigvis er noko som ei avis ville sjå på som viktig å satse på. Hovudinntrykket er at dette i tilfelle kunne fungere som ei kuriøs tilleggsteneste på nettsidene eller i avisappen. Potensialet blir å forstå på samen måten som sosiale medium som Facebook og Twitter som kan leie lesarar til avisa sine artiklar. Og når lesaren er fanga, håpar ein på at andre saker óg kan fenge lesaren. Samtidig kan den óg fungere i ein kommersiell tankegang med hyperlokalisert annonsering. For interesserte lesarar kan ein spesialisert funksjon som dette gjerne bli oppfatta som spennande, men til trass for alt dette kan marknaden vere for liten for ei avis. Og frå eit journalistperspektiv vert avisa sin muligheit til å prioritere innhaldet overfor brukaren redusert. Ein kan gjerne bøte på dette ved at ein passar på vektlegge aktualitet i større grad, for eksempel slik at ikkjelokale aktuelle nyheiter får ein plass i kombinasjon med det hyperlokale. Men om dette er nok for å handtere journalistanes kritiske merknader er usikkert.
Skynytt er eit eksempel på ei løysing som illustrerer potensielt spennande bruk av informasjonsteknologi innanfor mediebransjen. Ideen er ikkje vanskeleg å forstå og har til dømes gjennom lukketreffeigenskapen ein spesiell type verdi for brukarane. Samtidig er det tydeleg at bransjen har ei reservert haldning til denne typen småskalaprosjekt som kanskje ikkje har eit tydeleg og direkte økonomisk potensiale. Når konseptet óg på ein måte bryt med journalistens oppfatning av si eiga rolle, vert motstanden sterkare. Det er nok ikkje sikkert at slike hyperlokale tenester som Skynytt vert noko som vi kjem til å få tilbod om frå avisene sjølve. Det krevjast nok at konseptet er tydelegare og meir gjennomført frå forskarane si side før avisene vil bruke ressursar på dette.
Notar
1 http://arkivet.vg.no/
2 http://www.ta.no/arkiv/
3 https://developers.google.com/maps/documentation/geocoding/start
4 http://data.kartverket.no/download/content/geodataprodukter
5 http://www.geonames.org/
Referansar
B. Ekdale; J.B.Singer.; M. Tully; S. Harmsen (2015). Making Change: Diffusion of Technological, Relational, and Cultural Innovation in the Newsroom Journalism & Mass Communication Quarterly 92: 938958
A. Fagerjord (2015). Humanist evaluation methods in locative media design. Journal of Media Innovations 2(1) s. 107122
A. Foster; N. Ford. (2003.) Serendipity and information seeking: an empirical study. Journal of Documentation 59 (3):321340.
A. Gynnild (2013). Journalism innovation leads to innovation journalism: the impact of computational exploration on changing mindsets. Journalism. Vol. 15(6): 713730.
R Hirschheim; M Newman (1988). Information systems and user resistance: theory and practice. The Computer Journal 31 (5), 398408
P Hitzler; M Krotzsch; S Rudolph (2010). Foundations of semantic web technologies. Chapman and Hall/CRC.
A.R. Hevner; S.T.March; J. Park; S. Ram (2004). Design science in information systems research. MIS Q., 28(1), 75105.
A.Hevner; S. Chatterjee (2010). Design Research in Information Systems: Theory and Practice. Springer, New York.
K. Hess; L. Waller (2016). River flows and profit flows: The powerful logic driving local news. Journalism Studies, 17(3), pp: 263276
J. Hoem (2009). Personal Publishing Environments. Trondheim: NTNU (ISBN 9788247113745) 295 s. Doktoravhandlinger ved NTNU (2009:3)
J. Hoem; L. Nyre; J.M. Ringheim; B.Tessem (2016). Micropositioned Storytelling in Sound – Field Trial Evaluation of a Media Prototype. The Radio Conference 2016: Transnational Radio Encounters
S. Høst (2016). Avisåret 2015. Rapport nr 77. Høgskulen i Volda. ISBN 9788276613230
B. Johansen (2015). NamedEntity Chunking for Norwegian Text using Support Vector Machines. NIK: Norsk Informatikkonferanse 2015
G. Liestøl (2009). Situated Simulations: A Prototyped Augmented Reality Genre for Learning on the iPhone. International Journal of Interactive Mobile Technologies (iJIM) 3. s. 2428
A.S. Løvlie (2011). Locative literature: experiences with the textopia system. International Journal of Arts and Technology 4(3) s. 234248
C. D. Manning, P. Raghavan and H. Schütze (2008), Introduction to Information Retrieval, Cambridge University Press.
G. Marchionini (2006). Exploratory search: From finding to understanding. Communications of the ACM 49 (4):41–46.
L. Morlandstø; A. Krumsvik (red) (2014) Innovasjon og verdiskaping i lokale medier. Oslo: Cappelen Damm Akademisk.
N. Newman; R. Fletcher; D.A.L. Levy; R. Kleis Nielsen (2016). Reuters Institute Digital News Report 2016. Reuters Institute for the Study of Journalism. University of Oxford. ISBN 9781907384196.
L. Nyre (2014). God lokaljournalistikk berre på nett: Hypotetisk redesign av avisa Hordaland på Voss. I: Innovasjon og verdiskaping i lokale medier. Cappelen Damm Akademisk 2014 ISBN 9788202405809. s. 279302
L. Nyre (2015). Designing the Amplifon. A locative sound medium to supplement DAB radio. Journal of Media Innovations 2(2) s. 5873
L. Nyre; S. Bjørnestad; B. Tessem; K.V. Øie (2012). Locative journalism: Designing a locationdependent news medium for smartphones. Convergence. The International Journal of Research into New Media Technologies 18(3) s. 297314
A.W. Rivadeneira; D. M. Gruen; M. J. Muller; D. R. Millen (2007). Getting our head in the clouds: toward evaluation studies of tagclouds. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Jose, California, USA.
G.T. Ruud (2014). Journalistiske entreprenører. Medienes krise din mulighet. Oslo: Cappelen Damm Akademisk.
H. Sjøvaag (2014).Homogenisation or Differentiation? The Effects of Consolidation in the Regional Newspaper Market. Journalism Studies 15(5) s. 511521
T. Storsul; A. Krumsvik (red) (2013) Media Innovations: A Multidisciplinary Study of Change. Gøteborg: Nordicom.
K. Sørensen (2010). Det norske samfunn et innovasjonssystem? i I. Frønes & L. Kjølsrød (red) (2010) Det norske samfunn. 6. utgave. Oslo: Gyldendal Akademisk.
B. Tessem; S. Bjørnestad; W. Chen; L. Nyre (2015). Word cloud visualisation of locative information. Journal of Location Based Services 9(4) s. 254272.
O. Westlund; A.H. Krumsvik (2014). Perceptions of IntraOrganizational Collaboration and Media Workers’ Interests in Media Innovations. Journal of Media Innovations 1(2) s. 5274